AdaDelta
考虑优化问题:
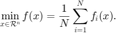
AdaDelta 算法基于 RMSProp 算法,对迭代增量 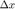 (相邻两步迭代的差值)做累计加权和。迭代格式为
(相邻两步迭代的差值)做累计加权和。迭代格式为
目录
初始化和迭代准备
输入信息:迭代初始值 x0 ,数据集大小 N ,样本梯度计算函数 pgfun ,目标函数值与梯度计算函数 fun 以及提供算法参数的结构体 opts 。
输出信息:迭代得到的解 x 和包含迭代信息的结构体 out 。
- out.fvec :迭代过程中的目标函数值信息
- out.nrmG :迭代过程中的梯度范数信息
- out.epoch :迭代过程中的时期 (epoch)信息
function [x,out] = AdaDelta(x0,N,pgfun,fun,opts)
从输入的结构体 opts 中读取参数或采取默认参数。
- opts.maxit :最大迭代次数
- opts.thres :增强数值稳定性的小量
- opts.rho :分量累积的权重
- outs.batchsize :随机算法的批量大小
- opts.verbose :不为 0 时输出每步迭代信息,否则不输出
if ~isfield(opts, 'maxit'); opts.maxit = 5000; end if ~isfield(opts, 'thres'); opts.thres = 1e-7; end if ~isfield(opts, 'rho'); opts.rho = 0.95; end if ~isfield(opts, 'batchsize'); opts.batchsize = 10; end if ~isfield(opts, 'verbose'); opts.verbose = 1; end
以 x0 为迭代初始点。计算初始点处的目标函数值和梯度,记初始时刻时期 (epoch) 为 0。
x = x0; out = struct(); [f,g] = fun(x); out.fvec = f; out.nrmG = norm(g,2); out.epoch = 0;
gsum 用来存储梯度分量的累计量。 xsum 用来存储增量分量的累积量。 count 用于计算时期 (epoch)。
gsum = zeros(size(x)); xsum = gsum; rho = opts.rho; count = 1;
迭代主循环
AdaGrad 的迭代循环,以 opts.maxit 为最大迭代次数。
for k = 1:opts.maxit
等概率地从  中选取批量
中选取批量  记录在 idx 之中,批量大小为 opts.batchsize。计算对应的样本的梯度。
记录在 idx 之中,批量大小为 opts.batchsize。计算对应的样本的梯度。
idx = randi(N,opts.batchsize,1);
g = pgfun(x,idx);
利用梯度分量累计量和增量分量累计对当前步的步长进行修正。注意到这里由于当前步的 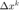 仍未算出,使用的是
仍未算出,使用的是 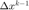 。
。
gsum = rho*gsum + (1-rho)*(g.*g);
dx = - sqrt(xsum + opts.thres)./sqrt(gsum + opts.thres).*g;
xsum = rho*xsum + (1-rho)*(dx.*dx);
x = x + dx;
每当参与迭代的总样本次数超过数据集的总样本时,记为一个时期 (epoch)。每一个时期, 记录当前的目标函数值和梯度范数,并令时期计数加一。
if k*opts.batchsize/N >= count [f,g] = fun(x); out.fvec = [out.fvec; f]; out.nrmG = [out.nrmG; norm(g,2)]; out.epoch = [out.epoch; k*opts.batchsize/N]; count = count + 1; end end
end
参考页面
在页面 实例:利用随机算法求解逻辑回归问题 中,我们展示了该算法的一个应用, 并且与其它随机算法进行比较。
其它随机算法参见: 随机梯度下降法、 AdaGrad、 RMSProp、 Adam。
此页面的源代码请见: AdaDelta.m。
版权声明
此页面为《最优化:建模、算法与理论》、《最优化计算方法》配套代码。 代码作者:文再文、刘浩洋、户将,代码整理与页面制作:杨昊桐。
著作权所有 (C) 2020 文再文、刘浩洋、户将